Optimizing for Long Term Outcomes


A promising approach to practical recommender alignment is to move from optimizing for short term outcomes (e.g. views, clicks) to longer term outcomes, outcomes that occur after multiple interactions and ideally multiple sessions (e.g. unsubscribes, monthly watch time).
It’s important to note that longer term outcomes are not necessarily more aligned (e.g. long term watch time optimization might lead to addiction). But most high quality forms of feedback are too expensive to provide frequently, so being able to measure and optimize for long term outcomes seems necessary, if not sufficient to build more aligned recommenders.
Conceptual Contributions
Advantage Amplification in Slowly Evolving Latent-State Environments
This paper has a great explanation for why optimizing for long term user value is so technically hard:
Users in real recommenders exhibit slow, long-term learning effects that can extend through tens of thousands of interactions
The user state is latent, and only impacts user behavior in a very noisy way (e.g the user might be learning to avoid using the recommender, but still binges occasionally)
Together this low signal-to-noise ratio slowly evolving environment is impossible to solve with supervised learning, hard to solve even with vanilla RL, but easy with RL augmented with their novel technique of advantage amplification.
The paper is also notable for proposing the very clean “chocolate-kale” toy model of long term value in recommender systems, where user engagement in the short term is always higher for bad content (‘chocolate’), but consuming healthy content (‘kale’) increases user engagement in the very long term.
From Optimizing Engagement to Measuring Value
This paper proposes anchoring “user value” to a concrete explicit user action (which can be very rare - in their case the user selecting “see less often” on a tweet notification). They then use this anchor to learn a model that predicts user value based on other, more common actions like clicks, long views, and likes. This model allows them to transform short-term low-quality feedback into long-term high-quality feedback. There’s also an interesting discussion of assessing the validity of the learned user value metric, in contrast to the usual industry approach of seeing if it improves engagement metrics.
Long-term Metrics in Production Systems
Aligning AI Optimization to Community Well-Being
This paper describes the nature of aligning recommender systems to human preferences broadly, and then reviews specific changes made to recommender systems in recent years by major content corporations, specifically Facebook and Youtube. Additionally, the author highlights several types of interventions that have been proposed during workshops on recommender system alignment that he believes are under-utilized.
There’s an analysis of various changes to recommender system objectives made by Facebook and Youtube. One especially interesting example is Facebook’s experimentation with a “meaningful social interaction” objective that is quantified as “probability that a piece of content causes a user to have a back-and-forth commenting dialogue, in a reply thread, with someone who they are Facebook friends with.” This caused me to reflect on my own experience using Facebook, noting that specifically many people often seem to complain about having political debates with strangers that they do not enjoy in retrospect, and that more recently I, anecdotally, have noticed that I do tend to have meaningful back-and-forth commenting threads with friends when viewing the Facebook timeline.
Incorporating More Feedback Into News Feed Ranking
This blog post reaffirms the degree to which Facebook is dependent on surveys of users to understand their preferences about what appears in the feed. Surveys are used, for instance, to get a sense for which types of posts users find most “inspirational” and then prioritizing those.
A full explanation of Facebook’s original efforts with surveying users to track things like preferred friends, facebook group importance, and links that are “worth your time” can be found over at Using Surveys to Make News Feed More Personal.
Several important implementation details about how these surveys work are left unspecified in these blog posts - e.g. how long after a post is viewed a survey is initiated, or whether the survey being triggered depends on some other user action. It seems like either of these would cause a noticeable response bias.
Facebook considered adding an “x” symbol to the top right of each post, which if clicked signifies that a user would like to see less of a certain type of content:
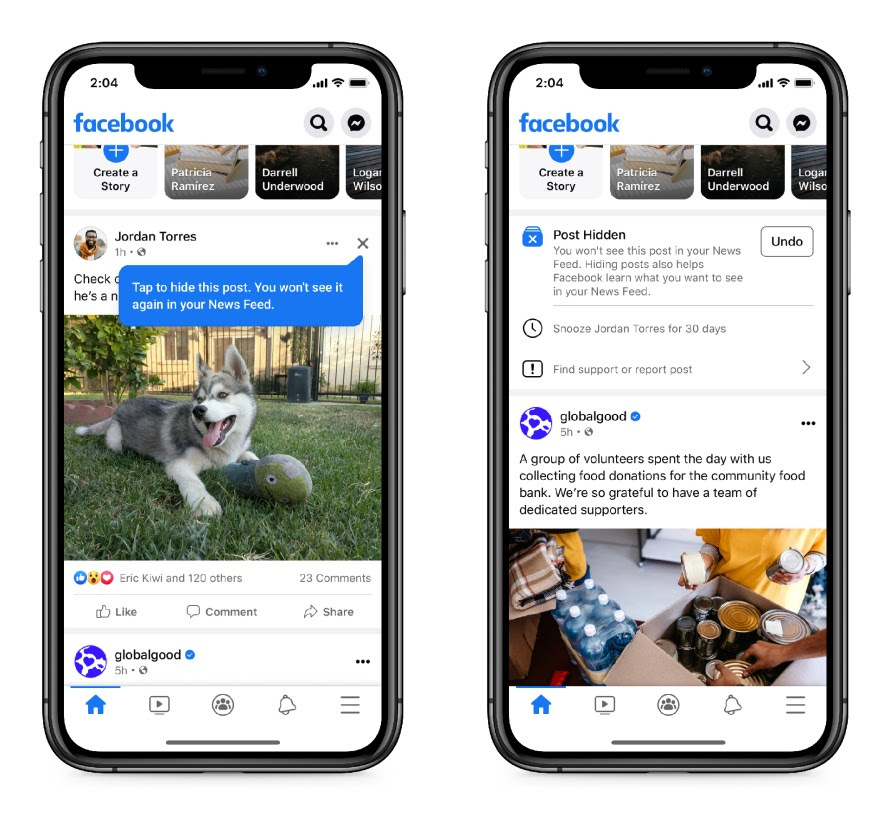
While this is much more prominent than the previous interface, it’s still not very accessible - the “x” button seems very easy to miss, and feels like an unusual and high-consequence action.
Netflix tracks shows by measuring ‘starters,’ ‘watchers,’ and ‘completers’
Netflix, famously, is careful about what data about show viewership it shares with the public and even its creators and producers, whose series fate depends on good metrics as evaluated by Netflix. This article explains some details revealed about how Netflix classifies users’ relationship to a series, specifically that it breaks down viewership audiences by “starters”, “watchers”, and “completers” to measure a series’ success. It also specifically prioritizes the funding of content that performs well against what is described as an “efficiency metric”. This metric is analogized to a ratio of a show’s potential to hang on to subscribers who would otherwise cancel their subscriptions or bring in new subscribers, over the net cost to users of the platform for having watched it, although it's unclear how the latter is quantified.
Written by Ivan Vendrov and Chris Painter. Please send us any interesting links related to recommender alignment, and see you next week!